特許技術はメーカーの財産である
当たり前や
ジムケラーはとっくに逃亡してるのはどういうことかね?
DEC Alphaはクレイジーだった
本とか嘘か知らんが、Jim Kellerは、1世代目zenだけじゃなく、2世代目zenの基本設計までしてから退職したとかなんとか
多分他のCPUもやってるよ
>>14 新型Radeon挿すとRyzenの封印が解除されるとかないかしら
>>11 最適化も適当なとこで止めないと
Bプランとか言う前にK12出せよ
>>23 K12がPC向けということはない
BulldozerにはPlanBはなかったようだけどね
http://www.geocities.jp/andosprocinfo/wadai17/20170520.htm >>26 >>29 TwitterのトレンドにNVIDIAが入るとかちょっと笑った
>>29 >>28 出遅れてるから
>>38 メイン用途は既に確立してるけどその他の用途でも使い道あるんじゃね?ってだけかと。
NVIDIA広報「興味を惹く為の釣りタイトルだと思いますが...」 日経ビジネスに"謎の半導体メーカー"と扱われた件でコメント [無断転載禁止]©2ch.net
機会学習はすでに端末側の争いに移行
>>41 >>42 ここからどう動くか見物だな 制御はエッジ側では尚更無理ゲー
懐かし過ぎて久々は
https://www.nextplatform.com/2017/05/22/hood-googles-tpu2-machine-learning-clusters/amp/ Racks B and C are a different story. Power delivery of 30 kilowatts would enable 200 watt power delivery to each TPU2 socket;
Google chose to scale out its original TPU as a coprocessor directly linked to a processor.
で、どうみたら機械学習で出遅れてるの?
演算力倍とFP16にしたから単純に160W超えちゃってるだろうけど
スケールアウトはどこも課題になってるし
>>59 リンク先に書いてるけど?
>>61 nvidiaもハードアクセラレータ積んできたし
NANDとNAND以外の不揮発性メモリではビットコストが違いすぎるからNANDみたいな低性能メモリがいまだに生き残る
>低性能メモリがいまだに生き残る
DRAM代替の不揮発性メモリとか、ほとんどUFOテクノロジーだよ
>>64 CNNでの画像認識は入力画像とフィルターを使いまわせるので
帯域が必要なのはLSTMやMLP、CNNでは特にいらんはず
>>75 >>76 こうしてやたらと攻撃的な>>76 が浮いたのであった >>78 >>79 量子コンピュータのチューリングマシンって、量子チューリングマシンのこと指して書いてる?
そろそろデータ揃えたりコード書いたりから解放されたい
エクサスケールの予算、十数年前のスパコン予算と比べて少なくなったのう
スパコンなんてXeonあれば十分だ
>>87 汎用でエクサが行けるのであれば、アプリケーションに特化した専用ハードウェアとかで
AMDしか使えない精神の不自由な人のことも考えてやれよ
>>93 >>91 >>94 まあ、やっぱり違うだろうな
会計っていってもいろいろやりかたがあるからね
発生主義か現金主義かであって
>>97 それにしてもA53売れすぎ
Cortexは一応汎用性を求めてるらしいので
A72-A73-A75 >>98 >>104 現金主義(爆笑)云々以前に、LakeCrestの部分的採用の可能性は書いてあるがKnightsHillを置き換えるなんて誤訳してるバカは一人しかいないよ
>>97 >>110 このアホはPre-Exaの意味も理解できないのかよ
>>114 >>116 >>117 パーツの納期の遅れ程度で計画そのものを大幅変更しない(というかできない)のはDOE案件見てりゃわかるだろ
top500は質低いんだろ
>>97 DOEはPre-Exa世代ではHPLだけでなくExaを見据えて帯域にフォーカスする(疎行列やFFTの性能でも高いものを目指す)と明言してるので
アメリカが豆腐をパクったようなインターコネクト出せばすぐに出せるのでは?
京の様にラック当たりのFLOPSが低いという代償を支払って0.5Byte/Flops
問題は、京やESみたいなのが優秀な分野の計算がどんどん少なくなってきてること
逆だろ
>>134 HPのメモリセントリックがものになれば疎密区別なく扱える時代がくるだろうか
hpのやつはそんなに電力効率上がる気がしないんだよな。データの移動コストが高そうに見える。
バッテリーに関しては、スマートフォンはテクノロジードライバーには成り得て無いな
ESってES2、ES3と増強してるけど京は京2や京3にしないのか?
2012年完成らしいから5年が契約期間だとすると
>>139 ARM CPUコアアーキテクチャ刷新の土台となる「DynamIQ」の実態 http://pc.watch.impress.co.jp/docs/column/kaigai/1051691.html あと、Intelは遥か前からbig.LITTLEやそれの類似を提示してるが
>>147 別の見方をすると、Hotchipsでなにもなければ
どのみち大口顧客に引っ張られるだろうしな
GoldmontはA72とA75の中間的なアプローチだね なんか某氏がARMも統合スケジューラ!効率的!って言ってた気がするが・・
A73,A75はIntとFPでレジスタセットが独立してて整数間とFP/SIMD間で統合してるし、整数レジスタとFP/SIMD間の転送を頻繁に使うことを想定してない。
Gemini Lakeとはなんぞ
林檎は今度はクアルコムから人材引き抜いてるらしいな。
iPhoneが生命線だからな
Windowsっていつになれば、4+1構成とか、big.LITTLE構成に対応するの?
国連が間違っていると閣議決定
big.LITTLEってやはり中途半端
性能はずっと据え置いたまま、ひたすら省エネを極める方向に開発を進めると思っていたけど
>>174 >>177 >>178 >>175 敢えて言わせてもらうが、スレチだ馬鹿。他でやれ
閣議で報告者関係ないって決まったし
スレタイも読めないのかこのバカ共は
他人から見る大変さと自覚する大変さが大きく違うタイプ
>>184 騒いでんのは当事者か、よほど暇な奴
といって無関係なはずのパンピーまでもが逮捕されまくったのが現実ですけどね
>>193 >>189 >>189 >>180 どこのニュースだ?
スパコンは半導体のプロセスの進化に合わせてチップを進化させていかないと陳腐化する
ホイホイと再設計していられないからな
>>172 >>207 Windows上でこのように表示されてるって事は
だから、私は約30秒を紹介するために過ごすことができます。
big Littleプロセッサが成り立つのは待ち時間なしで電源ONOFFを
MRAMって、14nmFinFETとかの汎用CMOSロジックプロセスに混載できるの?
212がとんちんかん過ぎて後々理解して見返したら赤面するだろうな
さて今後のCPUアーキテクチャとして要注目なのはIntelがNetburst以来20年ぶりにフルスクラッチしていると思われる新世代x86アーキだ
現行のSRAMより遅かったらダメだけどな
>>216 >>219 SkylakeがP6だっていうならGoldmontはP54Cベースだろ
>>223 >>224 VEX/EVEXネイティブなハードウェアでレガシーアプリをソフト的にダイナミックトランスレーションで実行するとかいうわりと先鋭的なハードだと言われてるが
>>223 >>230 >>231 VLIWは至高だ
denverもハード的にin orderなnative armだけど
3D MarkのPhysics上位勢は全部Core系なんだよな
>>231 トランスレート層が噛む前提だったら、表層のISAがx86_64である必然性も薄れるのかなあ
買収したSoftMachinesの技術でなんかしようとしてるかもね
AVXユニットの片レーンが80ビット浮動小数点を扱えるようにいびつな構造になってるのだが、x87をエミュレーションにしてしまえば64ビット×8, 32ビット×16の完全にシンメトリックな構造にできるから、そこが決め手なんじゃないの?
具体的には初期K8の64ビットモードでのx87と同様のペナルティが生じるかもね
つーか、コアあたりのトランジスタ数を減らす意義の大きいPhi向けならまだわかるんだけど、x87(あるいはレガシーSSE)を廃止することが劇的なパフォーマンスアップにつながるってのはにわかに信じがたい
gatherのコストがわからないバカは足し算すらできないことを自覚したら
32コアOpteronデュアル機を組むのを楽しみにしてます
宣言通りに買うのかどうか知らんが
Phiといや4オペランドてどうなるんかね?
>>251 >>251 >>259 >>258 RYZENの予測分岐はニューラルネットで
>>263 x87は、速度でなくてもいいが互換性のために残すって感じでいいでしょ?
ついでにSSEネイティヴ実行廃止の噂もあるけどソフト開発者に発破かける意味合いの方が大きいと思うけどね
>>261 >>266 MS「x86切り捨てんぞ」
何でも良いけどあの辺て「CPUが」扱えると書いて良いのか?
>>272 >>275 何百サイクルもかかるし他の命令の実行をロックするから、より効率的なソフト実装があるならそちらを使った方がいいよ
なんやこれ、Intel以外は詐称しまくりやんけw http://egg.2ch.net/test/read.cgi/jisaku/1496677423/175- >>276 >>277 超越関数という訳は、一瞬「お?」となる
>>280 >>281 >>282 有理数 <===> 有理関数
高階関数はこれらとは全く概念が異なる
昔の Visual Studio のヘルプ
三角関数は超越関数じゃなくね?定数係数線形微分方程式の解だから
>>289 >>286 >>290 >>290 >>278 >>291 >>296 >>296 逆だっての Skylake-Xのコアの大きさを殻割り画像やダイ写真から推測するとコア+L2C+L3Cで約16mm2
>>299 L3は減ってるでしょ
ダイサイズ測るついでにSkylake-XとSkylake-Sを同じ縮尺で並べてみた 14+同士で比較するならKabylake-Sのほうがいいかも
>>298 >>297 >>305 >>305 450mmなんてIntelはおろかTSMCも導入してないよ
>>304 右がSKL-Sで左がSKL-Xね ああ、右上のブロックがFMA(×2)だろうなとは察してたよ
団子は乗算器の回路規模なんて大したこと無いとかほざいてたけど結構な面積じゃん
AVX512_4VNNIWとかいう固定小数点の畳み込み演算用命令がKnightsMillで追加されるが
>>315 >>317 固定小数点の畳み込みなんてラーニング関連でないと使わないだろう。
補助なし300Wまで可能にするとかいう話があったな
>>323 >>326 >>317 糞手を100手読んでも無意味
>>328 行列の積の定義は覚えたの????
繰り返すけど4MIMWは16ビット整数値の畳み込み演算特化で行列積なんぞに使いようがない
こんな馬鹿と論ずる価値なし
畳み込み専用とかwww
AMDファンボーイの発狂具合が面白いがTwitterのハッシュタグ #Ryzen_SEGV_Battle 面白いことになってんな
> 繰り返すけど4MIMWは16ビット整数値の畳み込み演算特化で行列積なんぞに使いようがない
おいィ?
>>347 >>348 マイクロコード修正で直る、修正作業中で次のリビジョンで直る、黙殺する、
もともと高速なスイッチングが得意でないモバイルプ用のロセスルール使ってかつ普通はCPUに使わない高密度のセルマクロライブラリを強引に動かしてるから負荷によって何かエラー起こっても仕方ないと思いますけどw
>354
話は変わるがクソファンボーイ大絶賛のInfinityFabricはダイを並べるだけでスケールする魔法のインターコネクト技術という風潮があるが
>>356 来年は Cascade Lake で Intel persistent memory(3D XPointのDIMMタイプ)も
Xeon PlatinumがMCDRAMを載せるのか、載せるとしたらどんな構成なのかは知らないが、
多くのアプリではダイまたぎの通信が多少遅くても大して性能低下しない
>>359 Google Compute Engine の Skylake 32C版とかなら、32C/64TのVMを >>361 沢山のスレッドが動くサーバーなんかだと、メモリアクセスの面でも メモリ2chで8チップのNUMA構成自体はそれこそDDR1の時代のOpteron 8000番台からずっと実績あるからそれで行こうと思ったんでしょう
InfinityFabricてそもそもPHYがPCIeでしょ
そもそも全ダイがメモリフルロードしたらバス帯域飽和してダイ間通信に割り振れる帯域もない
>>366 ブロック図改めて見て
>>365 >>369 MCMのゴミを買うと言った覚えはない
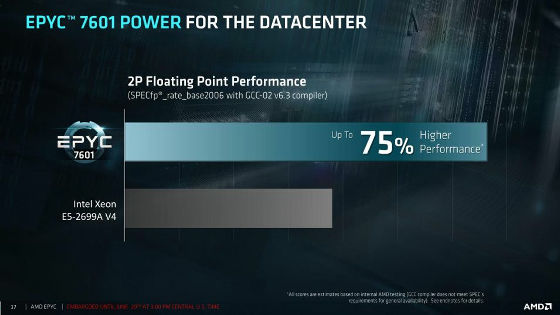
Broadwell の性能を越える
Are you native ? を自ら裏切る会社に守る約束などない
InfinityFabricは内部バスの簡易化と共通化がメイン だって本当に帯域狭いじゃん
中の人も未把握のSEGV出してる時点で歩留0%やん
AMDの中の人「uopcache無効にしてみろ(震え声」
ある種のワークロードではコア間インターコネクトの性能(レイテンシ/スループット)が必要だが、
少なくとも片側2車線道路が東西南北4方向に走ってるのを8車線道路って言ったら大嘘でしょ
まあ今のAMDの立場からすると8コアのMCMで開発コストを下げて
Intelが同じことをやれるのにトータルのスケーラビリティを犠牲にするので敢えてやらないことをやるのを賢いとは思わないけどね
MCMによる高密度実装とみなすなら、
雑に言えば16とか24とかのネイティブダイを設計してバリデーションする金も人も無いって話だと思うよ
てか、わざわざMCMででかいCPUに仕立て上げる必要あるのかね。コア数で
色々なトレードオフの結果としてMCMを選択する前提なら、
TDP 180W、パワーリミット240Wとかだと、それなりのCPUクーラー必要で密度
8C Ryzenダイと 4C+VegaのAPUダイの2つだけでIntel倒せそうなのがなんとも
>>391 >>393 >>394 1ダイ当たりXeon Dと同じ45Wまで下げても4ダイなら180Wで、下の画像 >>389 NaplesはPCIe3.0が128とDDR4の8チャンネルのSoCだから関係ないだろう
GeekbenchやSandraのスコア(超絶低性能)を片っ端から削除して回る程度のクオリティ
>>396 Ryzen Mobileになるとノートパソコン4コア8スレッドがメインストリーム
>>396 >>402 >>404 1700の65Wって、CINEBENCH(普通のソフトのCPU 100%はこのくらい マルチスレッドでに比較させたらこんなもん Naplesは16-32コアでTDP120-180W
>>409 >>407 AMDの広報担当者の(?)発想力だけはむしろ見習いたいが基本的に試験方法はちょっと残念
>>414 もっと重いPrime95とかでD-1541とD-1567(12C@65W)の消費電力を ダウンロード&関連動画>> VIDEO >>417 TDP超えたぶんの差分は外付けのVRが食ったって言い訳も成り立つかもね
>>421 Ryzenの場合、TDPとパッケージパワーのリミットは別腹らしいよ。 >>419 >>422 >>423 Prime95でもUPSの表示のアイドルとの差はTDPを僅か超える程度。 AMDは電力128WでもTDP95Wに抑えられる
>>424 OCって言うほど上がらんでしょ。 ダウンロード&関連動画>> VIDEO AMDがZenで高密度サーバやるって宣言してから
>>430 ワッパ気にしないのかよw ArkじゃなくてPDF化されてるデータシートの方見るともっと詳細な熱設計載ってるよ
分かったから暴れるなよw >>433 Xeon DのThermal/Mechanical Specification and Design Guideには >>432 ノートPCなんてコア数増やせば売れるもんじゃないのわかるだろうに
消費電力気にするのはバッテリー持続時間があるノートとかだけでいい
土木や建築業界では平均負荷の10〜100倍はマージン取るのが普通だが電気電子界隈は数割っていう皮肉があってだな
>>438 夏を乗り切れないRyzenちゃん
>>443 >>441 >>442 なんというかさ、モバイルだからって
微妙な問題ではある
一応TDP15WのCore i*-8xxxUに4コアはラインナップされてますよ
>>449 そんな「馬のツノ」のようなものを仮定するだけ無駄だよ
ウィップアタック・トゥ・ゴールデンボール、すなわち
NaplesがMCM構成であることは当時から広く知られていたにも関わらず
論理的じゃないね
「本当にBroadwellの性能超えたら」
>>454 >>457 何の仮定?
つーか、8コア×4の自称32コアの可能性一番先に指摘してたの俺だったけどな
むしろあの不具合抱えたままEPYCが発売できるかどうかの方が心配だな
Opteronを冠する32コアの製品が市場に存在しないし存在する予定もない。
>>466 当時の日本AMDの社長はMCMによるデュアルコアをマイクロプロセッサではなくロバ(donkey)だと言ったね
>>467 >>469 Are you native?ってAMDがMCMを馬鹿にしたからこそ
>>472 団子がdualEPYC環境IYHということでここは一つ
AMDは、7nmになってもGFの歩留まり悪くて8C/ダイのままだったりしないかね。
AMD「想定外のバグの修正で会計年度末のビリオンが足りない」
発想が違う
>>483 CCX3個とかバランス悪すぎるから、2CCXの8コアのままだろう
3nmの製品が出るのは何年後?
>>486 >>488 俺は32コアのOpteronを買うと宣言したがEPYCはOpteronでは無いから購入対象では無いな
>>488 NUMA構成の実態を隠蔽してNUMAチューニングできない状態にして回避とかw 複数MCMしていてもCPUとしては1つと認識させるだろ
ちなみに、4C/CCXの3CCX/ダイの48CでないとSP3使えないし2ソケも問題ある。 >>492 ソケットは実態通り見せても問題ないだろうね。でもNUMAノードはそれは別。 一度傷物になったブランドをAMDが使わないという想定の下に
>>470 x86サーバ市場では9割以上が2S以下の製品
>>490 そもそも、2ソケXeonは、ダイまたぎどころかソケットまたぎの通信があるわけだから、
AppleのA10XのCPUが高性能で一番注目されてよいはず
Purleyプラットフォームが1ダイあたり8〜16コアどまりでかつUPIの帯域がIFよりせまいならその仮定もまあわかるのだが現実世界の実装では最大28コア(特定顧客向けには最大32コア)までは内部ファブリックで高速につながったモノリシック構造なわけだから比較が成立しないね
やたら最強対決させたがってるけど
クリエイター気取りが 「誰もやらなかった事に挑戦する」とほざくが 大抵それは「先人が思いついたけどあえてやらなかった」ことだ
>>502 >>504 多くのサーバの利用方法では、EPYCのダイまたぎ通信はボトルネックとならない
「2ソケットの16コアBroadwell-Xeonに対して1ソケットの32コアEPYCは十分な対抗になりうるだろう」みたいなこと書いてるけど同じソケット数ならEPYCのほうが高価ってことだよねっていう
>>506 2ソケの製品が市場を席巻してる現状でMCMのNUMAは性能出ないとか言われてもハァ?としか
ダイまたぎ通信批判するのに、2ソケXeonは批判しない団子
よくわかってんじゃん
>>507 2ソケットで128レーン(ダイあたり16レーン)な
一般のDPサーバは普通GPUなんて刺さないので関係ないけど
>>514 ま、バス帯域飽和してら話にならんがな
>>518 DPサーバが一番売れてるっての、とりあえずバックエンドでもフロントエンドでもそれなりに潰しがきくからってのが大きいんだけどな
まあそれは、需要がどのくらいあるかだよね。
AMDがARMサーバ内定して結局失注したFacebook案件だって結局1Pの高密度ブレードというフロントエンド特価型サーバですし
昨今のシステムベンダーは「つぶしのきく万能のDPサーバ」をオンプレ運用ではなくAWS,Azure,GCPなどのクラウド大手に求めてて、結局そこはXeonが大半を支配してるから
今のEPYCは前座に過ぎないからね〜
CCX内であればXeonより速い筈
どこの並列世界の話か知らんが現実世界の実際のMicrosoftはQualcommと組んでARMをクライアント・サーバ共にx86に代わる選択肢として育てようとしてるわけでして
>>525 Google先行配備の32コア版Xeon実機と ま、MCDRAMオプション対応の時点で内部ファブリックのバンド幅がそれ以上あるのはわかるだろうに
それが何に跳ね返るかもお前ならわかる筈だよ
内部ファブリックの帯域で勝てそうになくなったら話題すり替えかな?
MCDRAMオプション? なんて話は一体どこから来たんだ
2chのメモリを4人5脚でドライブするなんちゃって8chメモリよりも、マザーボードの実装コスト抑えるために6chに抑えて、帯域が必要なアプリケーションのためにオンパッケージのMCDRAM追加バージョンをオプションで用意するほうが現実的なアプローチだと思うけどね。
まーだわからないか
>>530 >>536 >>538 >>537 >>529 8コアのRyzen1800Xでもシングル4000マルチ20000出るのでフェイクだと思う
団子はXeonのベンチマーク見てRyzenのものだの勘違いして暴れてたしなw >>535 最上位なんて持ち出さなくとも18コアの4ソケットで十分だな
>>546 4ソケットの時点で話しにならんな
Project Olympusで規格化されてた気がするので、MSは使うのかもしれない(実際に採用するとしてどれぐらいの規模がはまた別だけど)
大手が本格的に試験してたらsegvバグ?は見つかってただろという気もするので、矛盾しているようにも感じるが
4ソケットがダメな理由なんてないけどな
カーネルビルドで出るとか、サンプルをテストした初日で見つかりそうなエラーだよな
twitterでは冷却部即っぽいことも書かれてたが・・
>>553 分かってないな
一人褒め殺ししたいとしか思えない人がいる
最高クロックで駆動してもInfinityFabricのコントローラの、1ダイあたりのバンド幅が51.2GB/sしかないのに全chのメモリトラフィックがあつめられると豪語する謎
>>559 開発者にも原因不明のSEGVで突然落ちても困るんで基幹業務とは関係ない用途で模索するしか
確たる証拠もないのにSkylake-SPに480GB/sものMCDRAMが搭載されると信じ込む謎
ARM版Windows 10のx86エミュレーションがIntelの特許を侵害してるというが
ARM版Windows 10でx64のエミュレーションも将来的に可能になるようだけど
REXプリフィックスを一つ追加しただけの同人命令セットがオリジナルに採用されただけで全権掌握とは笑止
オリジナルのブログ記事を見る限りx86関連のパテント数が(買い上げたものも含め)ここ数年で激増してるので、何かしら触れるものがある可能性は否定できないね
>>567 革新的パッケージング技術だけで性能を40〜80%も向上させられる!!?
>>564 >>572 どちらにせよあれだけ脱Windowsみたいな活動しておいて
>>576 >>577 あれJavaとか使ってるんじゃないの?
>>580 http://pc.watch.impress.co.jp/docs/column/ubiq/616841.html Intelは、ARMアーキテクチャライセンスを持っている
守備の時セカンドボール拾われすぎなんだよなぁ
IoT向けSoCがARMに対抗し排除するどころかBluetoothモジュールにCortex-mを普通に載せてる
間違っちゃならんのは今回も競争相手はARMだが
>>588 Apple A*とかいう単コア性能が飛び抜けたオーパーツがあるが、あれが4GHzで駆動するわけじゃないし実際そうできない何かの壁が存在すると思ってる、あるいはIntelと不可侵条約でも結んでるかもしれないね。
>>591 該当のエミュレーションの特許がクロスライセンス適用外ならAMDが提訴されるだけだと思いますけど
>>595 まあ追加材料などなしに法廷闘争でMSが鮮やかに勝つ、というシナリオもありうる。
クロスライセンスの有利な条件引き出して終わりな気がしますけど
そもそもTransmetaとの訴訟合戦はIntelの方が和解金支払って調停してるので、エミュレーションに対する訴訟で文字通りIntelが勝った判例は無いです」
団子はマジでクズだな
わりと早くwindowsとx86の価値が下がってるよね
Windowsが自壊していってるからな
ios11でdocの追加やファイル操作が可能になるのは
>>605 >>600 まあIcestormから、Apple AのCPU性能は偏りがありそうだなと思うがね
>>592 そもそも環境庁更新してるのかね
これから俺はDELL男を最大限にサポートすることに決めた
>>612 中国がとくにチューニングもせずに適当に走らせてベンチで世界トップとった
DELL男スレのDELL男というのが見込みがあるので私の弟子にしようと思う
>>618 11月のtop500にはvolta更新組が入るかな
>>617 VoltaってIBMのCPUとの組み合わせでNVLINKって奴になるとか言うモノ
voltaってV100か
入るわけ無いだろ
今のところHPCGからみるに、Phiは良さげ
景気良く8192ノードとか16384ノードとか逝きましょうや
MCDRAMはどこに繋がるんですかねぇ
>>631 あいつがAtomコアは必要と力説してるから
>>633 Intel メッシュインターコネクト
>>635 >>635 >>635 なんか話聞いてると思想は両者近いものがありそうだな
単段クロスバーで配線だらけのチップでいいよ
Infinity Fabricは、実際にはDataFabricとControlFabricに分かれている 団子はもっともふうなことを言って適当な嘘をついてるだけだからな
てか東工大のTUSUBAME更新されるのね
Omni-Path経由でNV-Linkパケットをノードまたいで送受信できる
>>648 >>650 こんかいtsubame3.0がgreen500の1位かな
pezyは2つあったけど
CASCADE LAKEを待つスレに変わってしまったか?
爆熱の原因はAVX2/512とL2 1MBだろうから、Cannonlake以降も多分爆熱具合は変わらないと思うよ
メッシュによる発熱と、コア高密度過ぎで熱密度問題もありそ
>>664 green500でPEZY-SC2が7位に食い込んでるが
そらHPLじゃそうなるんじゃね?
>>658 >>671 >>672 >>661 後発のP100に採用件数で追い抜かれるはSkyLake-SPにワッパで負けるはKNLはいい所がないな。
ソフトによってXeon 2ソケットよりも圧倒的に高いパフォーマンス示してるから
話題が十年前のIntelとAMDがひっくり返っとるな
programmerに優しいのはIntelしかあり得んからなあ
>>681 プログラマに優しいのはIntelじゃなくてMSだろ
その割にプログラマ離れが酷くてMacやLinuxに逃げた層を取り戻そうとAtom派生のエディタ作ってますけど
>>685 地球にやさしいプロセサはないのか?
脳にエラッタがあっても誰も保証してくれないのに比べればIntelもAMDも神サポート()
かつてLinpack番長っていわれたGPUが、いまやLinpack番長じゃなくなってきてるからね
GPU勢がLinpack番長じゃなくなりあらゆる演算が高速化したのは、NVLinkのおかげだろうな
コア性能・メモリ帯域・ノード間通信どれも既存の大型スーパーコンピュータの圧勝
最近流行りのGPUのみのノードをInfinibandやOmni-Pathで繋げる方式だと
日本のIT・コンピュータ系メディアで、NVLinkの凄さをまともにわかってる人、それを記事にしてる人は少ない
>>697 そらNVIDIAさんも何回もOptimization for HPCGをやってきてるからな
>>695 まさか製造プロセス出されるとは思わなかったもんでね
そりゃあ初期の頃はドライバーが貧弱で最適化が進めば性能が上がるのは普通だ
top500ので公開されてる総コア数からアクセラレータ分引くと
NVlinkを少し調べてみた ソフトの最適化はハードの性能を極限まで引き出すことだがハードの制約は超えられない
>>710 AMDのVegaやNaviはHBCCって機能でSSDやHDDを巨大なキャッシュとして扱うことが出来るらしい まあP100を、KNLとHPCで使うアプリとの比較を見せないことから
>>718 EPYC1ソケット VS Xeon 2ソケット >>718 EPYCのスペックと筆者予想価格 >>718 >>722 天河2はその5倍くらいありますけど
そうなのか
>>727 実は本当にベンチのために最適化しまくってたのは
天河2号のインターコネクトはAriesよりずっと低速だし、ましてノード数が多いとなればホップ数が増大するぶん実行性能比はさらに不利になる
F1カーは悪天候下では最高60km/h程度まで落として走る
クソコテがまたトンチンカンな喩え出してんな
HPCGはコア数或いはノード数が増えれば増えるほど、スコアの伸びが悪くなる…基本的には
団子はintelスレで7900Xの爆熱メッシュバスの擁護でもしてろよw
専門家ならryzenのコンパイルエラーの原因究明してこいよ
>>727 まあPCIeが必須な限りは、どんな高速インターコネクトでも厳しいと思うけどね
OpenCAPIがあるじゃんIntelハブられてるけどAMDいるぞ
あの比較、CPU部は下手すると何も寄与してないのではと思ってた
小規模だと無意味だろうな
>>742 それとGPUで気にくわんのはコードが膨大だわ、継続性がないわと
まあ、あれはあれでPhiより大きな市場を確立してるからその顧客のためにやるでしょ
なんだかんだPhiは筋がよいと思うけどな
GPGPUの問題点 http://ascii.jp/elem/000/001/039/1039493/ >>748 現実はこんなもん 機械翻訳はネイティヴ32コアを出すと宣言したんだからその落とし前つけろや
Opteronの名前はAMDのサーバ向けCPUの代名詞として広く認識されていた
intelだってニコイチ出してたろ
>>758 Pentiumを安物の代名詞にした会社もありますね
intelはPentiumの名前にひどいことしたよね
許すか許されないか以前にお前に許しを乞う義理もないわ
>>761 どの面下げて、こんなに偉そうな事が言えるんだろうね
OpenPowerってバカかこいつw
団子は一体何と戦ってるんだろうか
Skylake Xeonってそんなにflops出るんだっけ? 2Sで追いつくかどうかぐらいなのかなと思ってたけど
>>750 あ、すまんすまん
>>764 >>765 >>767 >>776 >>736 >>418 SPECint_rateは、たぶん得意な部類じゃないかな
32コア、8chメモリ、PCIe 128レーン、チップセット不要
面白いとすると、1Sで大量IOみたいな使い方かなあ。いわゆるマイクロサーバの亜種か
GFの7nmは低クロックなモバイル向けじゃなく高クロックなハイパフォーマンス向けとのこと
EPYCはXEONにボリュームゾーンで対抗できる経済的合理性がある
>>781 8ソケットぶんのリソースぶち込んで2ソケットサーバでっち上げたんだから逆にこのくらいのスコア出さないとね
>>787 相手にされないと寂しいからこっちに来てんのかな?
団子早く消えないかな…
>>796 思ったよりベンダーの支持が集まっていてぐぬぬ状態なのだろう
皆んなintelのボッタクリと横暴さに辟易してたんだろうね
>>803 >>804 https://srad.jp/submission/71785/ 団子は当然32コアEPYC買うんだよな?
>>656 IntelやIBM,Qualcommのサーバに求められるのはただ一つだけ
>>807 >>806 >>812 偶発であれなんであれ誤ったジャンプ先が64バイト前のアドレスってわかってるなら、そこにコード仕込んでおけばexploitとして使えるよな
飛び先が何個あると思ってんだか
サイボウズラボ竹迫氏の論文で提唱された攻撃手段は、JITがバグでジャンプ先アドレスの計算を間違える必要があるんだけど、CPUがそれを提供してるなら応用できる可能性があるんよ
>>817 >>817 >>821 日本語を正しく読むと団子はEPYC32コアで組まなけりゃならなくなるなw
>>824 団子が深刻だということは大した問題じゃないということだな
>>826 >>826 >>822 L1キャッシュが命令とデータで分かれてることすら知らないんだろこのボケ
>>830 >>833 >>834 全額返金してくれるわけでもないのにそんな無駄な工数かけるかよ
団子が騒げば騒ぐほど事態は好転するからもっと騒げばいい
>>836 8コアマシンが欲しかっただけのエンジニア、さすがに泣いているとは思う
団子が騒いでるだけで、まあ1年もしたらあいつが暴れてたのなんだったろて話になる
>>840 断片的な話を読む限りだと、
>>830 >>836 >>843 団子は知ったかぶり多すぎだろ
>>838 >>844 エコシステムに入ってるRedhatやSuseがどういった対応を取るかだなあ
>>851 キャッシュと書いてるからデータのことだという思い込みってひどすぎるだろ
>>854 なんで突然データキャッシュの話が?
まず事実として、
こんな場末の2chの自作板のAMDスレですらないスレでも議論が白熱してるんだよな
CPUの動作をまるで理解してないから、発見者の書き込み内容を理解できない
指摘させると、全くトンチンカンな>>851 みたいな書き込みをしたあと、>>856 みたいな捨て台詞を吐く >>855 データを間違えるって主張してるの >>820 こいつだし 「ジャンプ先のアドレスのデータ」
>>829 >>822 >>865 それでトンチンカンな発言を繰り返してたわけか
団子がトンチンカンな理由はわかったが、
もうちょっとちゃんと書くと、飛び先のアドレス計算を間違ったという根拠
命令=データとかまずそこから知恵遅れ
で、
馬鹿断固はintelスレで大人しくしてろ:∀`・,,)
命令をデータ扱いする根拠の方が知りたいな
もう知恵遅れの2IDをあぼーんしとけば十分だね
今回は大きな思い込みが2個
あぼーん連発してるし
さすがに、そこらじゅうに書いてる「飛び先を間違う」発言はもうしなくなると思うけど
命令がデータだとするならL1キャッシュが命令キャッシュとデータキャッシュに分かれてる言葉の概念すら否定されますよ
アドレス計算までは正しいけどそれを使う瞬間に不正な値になってるのか?
狭義の「データ」、広義の「データ」が存在することもわからない
>>892 なんか伸びてると思ったら団子と変なのがレスバトルしてた
プログラム上でも命令とデータはコードセクション、データセクションに分かれててプログラムローダが読み出した時にそれぞれの属性つけてメモリ上に展開するんですけどね。
>>892 団子はまだ本題と無関係なトンチンカンな事を書き続けてるが無視する
>>892 >>893 ジャンプ先のアドレス計算を間違う
それにしても団子の勘違いの言い訳が見苦しすぎてwww
自演?
64バイトずれた命令を実行してそうっていうことまではわかっても、
どうみても命令コードの飛び先の保護違反で例外が起きてるのにどっかの頭の悪いのが
>>838 >>906 >>906 >>909 64バイト計算を間違う演算器ってどうやったら作れるの
PhaseLockLoopが甘くて同期ズレでIPが飛ぶってのは
竹迫論文を英訳して海外の変態どもにシステムを乗っ取るコード書かせるコンテスト開催してみたらいいんじゃね?
つかApple以外の最近の採用例を知りたい
クソ団子、古巣のintelスレでも叩きまくられてワロタw∀`・,,)
HelioX30も一応PVRな
年寄りってのは頭が固くて何も生み出そうとしないくせに
ARMについでImaginationまでもか。
>>918 そもそもCPUコアの命令とデータの扱い方の違いさえわかってれば論争なんて起きようが無いし
>>923 分岐予測とかの絡みで投機的なPCの書き換えが発生するときにdecoded Icacheがズレた番地の命令を吐いちゃうとかそんな感じのエラッタなんだろうか
条件分岐はあんまり関係なくて、保護違反が起きた時の共通の条件としてジャンプ命令(call命令も?)トレースログが止まってて64バイト手前のアドレスを呼んでるらしいとのこと
>>926 >>923 ただripの64バイト手前を実際にコードシーケンスとして実行してるのか、あるいはフェッチするだけに止まってるのかなんてのはもう少し見ないとわからん
>>926 まあ、SEGVで止まらなかった場合の挙動のエビデンスは必要だな
64バイト前の命令を実行した根拠が書かれてるんだけど
もうお腹痛いよこれ
>>933 団子アホすぎだろ
正常動作前提のXeonに大勝利とかも意味ねーからバイバイ
ヒントを教えよう
DropboxがQualcommのサーバCPUあたりにリプレース発表したらおもしろいんだけどAMDファンボーイが逆神すぎて草
EPYC大規模導入予定の会社は、いまごろ裏でAMDに例のバグがEPYCに影響あるのかどうか聞いてるでしょ?
>>941 >>946 でもそんなエラー出してたら負荷テスト通らないんじゃないの?
>>946 >>949 スラドでは分岐予測基の誤作動の可能性もあるって書かれてた
141 名前:,,・´∀`・,,)っ-○○○[] 投稿日:2016/11/14(月) 20:08:59.13 ID:0Q4rwlJ0 [3/9]
>>955 負荷テストは通ってgccでSEGVを出しやすいのかは団子先生がEPYC買って解説してくれるはず。
,.::., -― -- :,:、
Dropboxが大規模障害だして阿鼻叫喚とかもあるのかもな
そんな大事なデータをローカルバックアップしてなかったの!?
発表がない以上は新ステップで直ってる保証はどこにもないからな
即値ジャンプでエラー出てるのに分岐予測のわけ無いだろ
どうもHW要員くさいな
>Zenがクソ性能であることに私は年末ボーナスを賭けてもいいよ
905 名前:Socket774[sage] 投稿日:2017/06/23(金) 20:42:23.31 ID:KE9/Q9Ag
笑笑w >>972 >>972 何言ってんだこいつ
>>974 コピペ粘着の度がすぎる感は否めないが
EPYCデュアルで組んでごめんなさいするまでは、
1Pでもメモリ8ch、PCIex16x8本出せるのは強力だな
リリース前に修正不能な重大なバグが発覚したら延期するだろ
詳細がわからないから延期の判断が出来ない
偉い人が知らないって可能性も
サーバーメーカーも事前検証して把握くらいは当然してるだろう
パフォーマンスでフルボッコにされた団子が
知らないのに知ったかぶるから
>>977 水星が地球に落ちてきたら水資源問題解決スルー?
水星が落ちてきたら人類が滅亡するので今現在人類が直面しているあらゆる問題が無くなる
>>981 >>992 まあ、逆にBluemixの納入先業者トップはSupermicroなんですけどね
>>998 それは定説じゃねーよ
lud20200523043210ca
このスレへの固定リンク: http://5chb.net/r/jisaku/1495257064/ ヒント: 5chスレのurlに
http ://xxxx.5ch
b .net/xxxx のように
b を入れるだけでここでスレ保存、閲覧できます。
TOPへ TOPへ
全掲示板一覧 この掲示板へ 人気スレ |
>50
>100
>200
>300
>500
>1000枚
新着画像 ↓「CPUアーキテクチャについて語れ 36©2ch.net YouTube動画>2本 ->画像>40枚 」 を見た人も見ています:・CPUアーキテクチャについて語れ 35 CPUアーキテクチャについて語れ 30 CPUアーキテクチャについて語れ 32 CPUアーキテクチャについて語れ 39 CPUアーキテクチャについて語れ 17 CPUアーキテクチャについて語れ 57 CPUアーキテクチャについて語れ 48 CPUアーキテクチャについて語れ 49 CPUアーキテクチャについて語れ 50 CPUアーキテクチャについて語れ 40 CPUアーキテクチャについて語れ 56 CPUアーキテクチャについて語れ 46 CPUアーキテクチャについて語れ 44 [RISC]CPUアーキテクチャについて語れ![VLIW]2 【CPU】AMD、新「Zen 2」アーキテクチャで12コアの「Ryzen 9 3900X」 投資オープンチャットについて語れ 國又について語れ 貧乏飯について語れ 貧乏飯について語れ netkeibaについて語れ 西友の弁当について語れ 残価設定ローンについて語れ 東邦産業研究所について語れ ★栃木の山について語れ Part17 クリスティアーノ・ロナウドについて語れ コテハン「このレス転載禁止」について語るスレ AMDの次世代APU/CPU/SoCについて語ろう 312世代 AMDの次世代APU/CPU/SoCについて語ろう 306世代 AMDの次世代APU/CPU/SoCについて語ろう 307世代 AMDの次世代APU/CPU/SoCについて語ろう 304世代 AMDの次世代APU/CPU/SoCについて語ろう 301世代 AMDの次世代APU/CPU/SoCについて語ろう 311世代 AMDの次世代APU/CPU/SoCについて語ろう 313世代 (551) Intelの次世代CPU/SoCについて語ろう 81 Intelの次世代CPU/SoCについて語ろう 82 Intelの次世代CPU/SoCについて語ろう 80 AMDの次世代APU/CPU/SoCについて語ろう 246世代 AMDの次世代APU/CPU/SoCについて語ろう 285世代 AMDの次世代APU/CPU/SoCについて語ろう 253世代 AMDの次世代APU/CPU/SoCについて語ろう 274世代 AMDの次世代APU/CPU/SoCについて語ろう 299世代 AMDの次世代APU/CPU/SoCについて語ろう 295世代 AMDの次世代APU/CPU/SoCについて語ろう 272世代 AMDの次世代APU/CPU/SoCについて語ろう 250世代 AMDの次世代APU/CPU/SoCについて語ろう 279世代 AMDの次世代APU/CPU/SoCについて語ろう 234世代 AMDの次世代APU/CPU/SoCについて語ろう 288世代 AMDの次世代APU/CPU/SoCについて語ろう 284世代 AMDの次世代APU/CPU/SoCについて語ろう 277世代 AMDの次世代APU/CPU/SoCについて語ろう 282世代 AMDの次世代APU/CPU/SoCについて語ろう 273世代 AMDの次世代APU/CPU/SoCについて語ろう 244世代 AMDの次世代APU/CPU/SoCについて語ろう 276世代 AMDの次世代APU/CPU/SoCについて語ろう 283世代 AMDの次世代APU/CPU/SoCについて語ろう 264世代 AMDの次世代APU/CPU/SoCについて翻訳しよう8スレ目 AMDの次世代GPUについて語ろう AMDの次世代GPUについて語ろう 2世代 AMDの次世代GPUについて語ろう 6世代 PureVideoについて語るスレ Ver.7 NVIDIAの次世代技術について語ろう パソコンについて相談があります Intelの次世代技術について語ろう 90 Intelの次世代技術について語ろう 99 Intelの次世代技術について語ろう 92
08:00:59 up 39 days, 9:04, 0 users, load average: 7.75, 7.93, 7.49
in 0.031529903411865 sec
@0.031529903411865@0b7 on 022122